
Tylko 61% ze wszystkich podstron Walmarta (https://www.walmart.com/) znajduje się w indeksie wyszukiwarki Google, a znane powiedzenie mówi przecież, że jeżeli nie ma Cię w Google, to nie istniejesz. Nie da się zaprzeczyć, że jest w nim sporo prawdy.
Jak zatem można świadomie usuwać strony z indeksu Google? I po co w ogóle to robić?
Wbrew pozorom nie jest to oznaka szaleństwa. Okazuje się, że nie wszystkie podstrony witryny powinny znaleźć się w indeksie wyszukiwarki dla dobra witryny jako całości. Mowa tu w szczególności o podstronach, których celem jest zupełnie coś innego niż generowanie ruchu z organicznych wyników wyszukiwania. Mogą być to podstrony z mało istotnymi z punktu widzenia wyszukiwarek internetowych treściami lub powstałe w wyniku np. personalizacji oferty.
Więcej na ich temat, a także o powodach oraz sposobach wykluczania podstron z indeksu wyszukiwarki przeczytasz w poniższym artykule.
Crawl Budget – czym jest i dlaczego nie warto go marnować?
Zanim podstrona znajdzie się w wyszukiwarce, muszą odwiedzić ją roboty indeksujące i przeanalizować jej treść. Po wykonaniu tych czasochłonnych zadań algorytm wyszukiwarki decyduje czy warto dodawać ją do indeksu, czy nie.
Moce przerobowe robotów indeksujących są jednak ograniczone.
Owe zasoby określamy za pomocą terminu Crawl Budget. Kryje się pod nim liczba podstron, które roboty Google są w stanie zaindeksować w obrębie danej domeny. Polskim odpowiednikiem tego pojęcia byłby więc po prostu budżet indeksowania witryny.
Już teraz podpowiemy, że to właśnie ze względu na niego należy wykluczać niektóre strony z indeksu Google. W końcu po co marnować Crawl Budget na podstrony, których obecność w indeksie nie przynosi żadnych korzyści z punktu widzenia widoczności strony w wyszukiwarce?
Czym jest indeks Google? Czy wszystkie strony powinny się w nim znaleźć?
Na tym etapie rozumiesz już pewnie, że indeks wyszukiwarki Google to zbiór wszystkich stron internetowych dostępnych w organicznych wynikach wyszukiwania. Nie znajdziesz tam wszystkich stron istniejących w Internecie. Są tam tylko te strony, które były wcześniej odwiedzone przez robota indeksującego i nic nie stanęło na przeszkodzie, aby zostały zaindeksowane.
Najnowsze dane mówią, że około 15-20% stron egzystuje poza indeksem wyszukiwarki Google. Dlaczego tak się dzieje?
Wspomnieliśmy już, że pozwolenie na indeksowanie wszystkich podstron witryny może być marnowaniem ograniczonego Crawl Budgetu. Przyczyn, by wykluczać podstrony z indeksu jest jednak więcej. Nie ma potrzeby, by w indeksie znalazły się podstrony z niskiej jakości treściami oraz podstrony bez unikalnych treści.
Konkrety? Oto przykłady stron, których indeksowanie warto blokować:
- podstrony z wynikami wyszukiwania,
- podstrony z wynikami filtrowania produktów w sklepach internetowych,
- podstrony z wynikami sortowania produktów,
- podstrony powstałe w wyniku personalizowania produktu,
- podstrony bez unikalnych treści,
- podstrona logowania, rejestracji, podstrona z regulaminem oraz koszyk w sklepie internetowym.
Jak sprawdzić czy podstrona znajduje się w indeksie Google?
Najłatwiej to zrobić wpisując odpowiednie komendy do wyszukiwarki:
- site:nazwadomeny (np. site:performancemedia.pl) – Google wyświetli wszystkie zaindeksowane podstrony ze wskazanej witryny.
- inurl:frazy kluczowe (np. inurl:performance media blog) – Google pokaże zaindeksowane wyniki zawierające dane słowa kluczowe w swoich adresach URL.
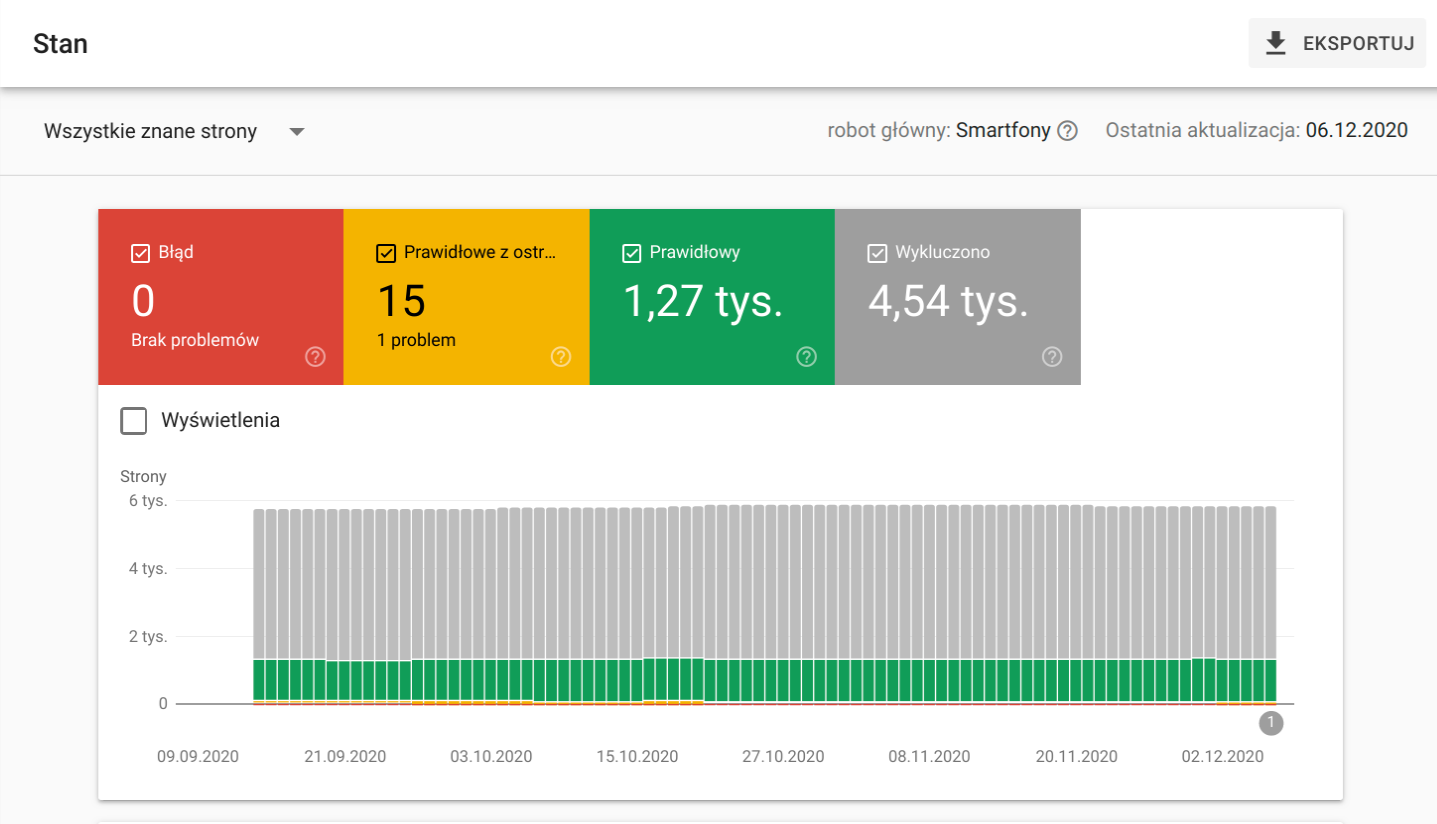
Stan indeksacji poszczególnych podstron można również sprawdzić w narzędziu Google Search Console. Aby to zrobić, należy przejść do zakładki „Indeks” -> „Stan”.
Pamiętaj, że jeżeli po prostu wpiszesz nazwę swojej strony w Google czy powiązane z nią wyrażenie, a ta nie pojawi się w wyszukiwarce, nie oznacza to wcale, że jej tam nie ma. Być może jest, ale na bardzo dalekich pozycjach, do których nie jesteś w stanie dotrzeć. Dlatego by mieć pewność, czy dana strona jest zaindeksowana radzimy korzystać z opisanych wyżej sposobów.
Jak sprawdzić wersję podstrony zaindeksowaną przez Google?
Aby sprawdzić wersję podstrony zaindeksowaną przez wyszukiwarkę Google należy użyć polecenia cache, po którym należy podać adres URL podstrony, której wersję w indeksie Google chcemy sprawdzić:
cache:adres-URL-podstrony
Gdybyśmy chcieli sprawdzić wersję aktualne czytanego artykułu w indeksie Google należałoby użyć polecenia:
cache:https://lumo.pl/blog/noindex-i-nofollow-czym-sie-roznia-i-jak-je-stosowac-aby-wykluczyc-strony-z-indeksu-google/
Wiesz już, czym jest indeks Google i że nie wszystkie podstrony w obrębie witryny powinny być indeksowane. Przejdźmy teraz do omówienia sposobów, które pozwolą Ci wykluczyć konkretne podstrony z indeksowania.
Noindex, czyli blokowanie indeksowania podstrony poprzez meta tag noindex
To prawdopodobnie najczęściej używany sposób, aby zablokować indeksowanie danej podstrony.
Aby zablokować indeksowanie danej podstrony, należy w sekcji <head> strony umieścić następujący meta tag:
<meta name=”robots” content=”noindex”>.
Natomiast jeśli z jakichś przyczyn chodzi tylko o blokadę indeksowania przez roboty indeksujące Google, to wtedy należy użyć meta tagu:
<meta name=”googlebot” content=”noindex”>.
Meta tag noindex pozwala też na usunięcie z indeksu już zindeksowanej podstrony. Zablokowanie indeksowania podstrony już zindeksowaniej poprzez dodanie tego meta tagu sprawi, że po kolejnej wizycie na tej podstronie robota indeksującego zostanie ona usunięta z indeksu.
Nofollow – zablokowanie przekazywania reputacji podlinkowywanym stronom
Każdy, kto kiedyś słyszał o SEO, wie, że jednym z filarów pozycjonowania jest pozyskiwanie linków (tzw. link building). Nie wszyscy zdają sobie jednak sprawę, że niezwykle istotnym elementem tego procesu jest przypisanie linkom odpowiednich atrybutów.
To raczej oczywiste, że każdy link jest powiązany z miejscem, do którego prowadzi. Relację tę określa się za pomocą wartości atrybutu rel linka.
Domyślnie atrybut rel linka ma wartość dofollow (rel=”follow”). Atrybut ten nie jest obowiązkowy, a linki nie posiadające tego atrybutu są traktowane jako linki dofollow. Link o takim atrybucie przekazuje część autorytetu strony (tzw. link juice) z linkiem podlinkowywanej witrynie, dzięki czemu podnosi ranking witryny, do której prowadzi.
Atrybut ten może też mieć wartość nofollow (rel=”nofollow”). Używa się go w przypadkach, gdy nie chce się przekazywać autorytetu strony podlinkowanej witrynie. Nie blokuje to jednak indeksowania podlinkowanej strony. Roboty indeksujące mogą podążyć za linkiem nofollow i zaindeksować podstronę, do której link typu nofollow kieruje.
Linki z atrybutem rel o wartości nofollow warto stosować w przypadku podstron, nad którymi właściciel danej strony nie ma pełnej kontroli. Dotyczy to np. linków w reklamach, komentarzach, we wpisach gościnnych czy linków osadzonych w wideo lub infografikach.
Aby wszystkie linki na danej podstronie były traktowane jako linki nofollow należy umieścić w sekcji <head> podstrony kod:
<meta name=”robots” content=”nofollow”>.
Jaka jest różnica pomiędzy meta tagiem noindex i meta tagiem nofollow?
Metatag noindex i meta tag nofollow pełnią zupełnie różne funkcje. Podsumujmy zebrane wyżej informacje:
- Meta tag noindex informuje roboty Google, by nie uwzględniały danej witryny w wynikach wyszukiwania.
- Atrybut nofollow sprawia, że linki na stronie nie przekazują reputacji podlinkowanym witrynom.
Innymi słowy linki na podstronach z meta tagiem nofollow nie przekazują części reputacji linkowanym witrynom. Boty indeksujące mogą podążyć za linkami tego typu i zaindeksować podstrony, do których te linki prowadzą.
Atrybut noindex sprawia, że linkowana podstrona nie jest dodawana do indeksu wyszukiwarki.
Tag noindex powoduje też usunięcie z indeksu wyszukiwarki podstrony, do której został dodany.
Kiedy stosować tag noindex, a kiedy nofollow?
Bardzo często oba polecenia stosowane są równocześnie. W końcu jeżeli strona jest opisana tagiem noindex oczywistym jest, że umieszczone na niej linki również nie powinny interesować Google. W kodzie wygląda to następująco:
<meta name=”robots” content=”noindex, nofollow”>.
Jaki jest skutek takiego działania? Roboty nie indeksują danej podstrony, a linki wychodzące z danej podstrony nie przekazują autorytetu linkowanym witrynom.
Blokowanie indeksowania podstron – inne sposoby
Użycie tagu noindex oraz atrybutu nofollow to nie jedyne sposoby, by zapobiec indeksowaniu określonych podstron. Można zastosować także:
Zablokowanie indeksowania podstrony poprzez instrukcję w pliku robots.txt
Robots.txt to plik umieszczany na serwerze, który odpowiada za komunikację z robotami indeksującymi wyszukiwarek internetowych. W dużym uproszczeniu służy do określania, do których zasobów boty indeksujące powinny mieć dostęp, a do których nie.
Zanim jednak użyjesz go do blokady indeksowania części zasobów strony, musisz stworzyć taki plik i umieścić go na serwerze. By sprawdzić, czy twoja strona ma już taki plik, przejdź pod adres:
twojadomena.pl/robots.txt.
Plik robots.txt wygląda na przykład tak:
https://lumo.pl/robots.txt

Gotowe? By zablokować wybrane podstrony przed indeksowaniem, dodaj do pliku robots.txt następującą instrukcję:
Disallow: /fragment-adresu-URL
Instrukcja ta spowoduje, że zablokowane przed indeksowaniem zostaną wszystkie zasoby, których adres URL zaczyna się do twojadomena.pl/fragment-adresu-URL
Przykład: Jeśli chcielibyśmy w ten sposób zablokować indeksowanie naszego bloga, to w pliku robots.txt naszej strony byłby następujący kod:
User-agent: *
Disallow: /blog/
Trzeba liczyć się jednak z tym, że niepoprawna konfiguracja pliku robots.txt może zakończyć się dla strony katastrofą. Jeśli nie posiadasz wystarczającej wiedzy technicznej, szczerze radzimy wykluczać podstrony z indeksu tylko za pomocą meta tagu noindex.
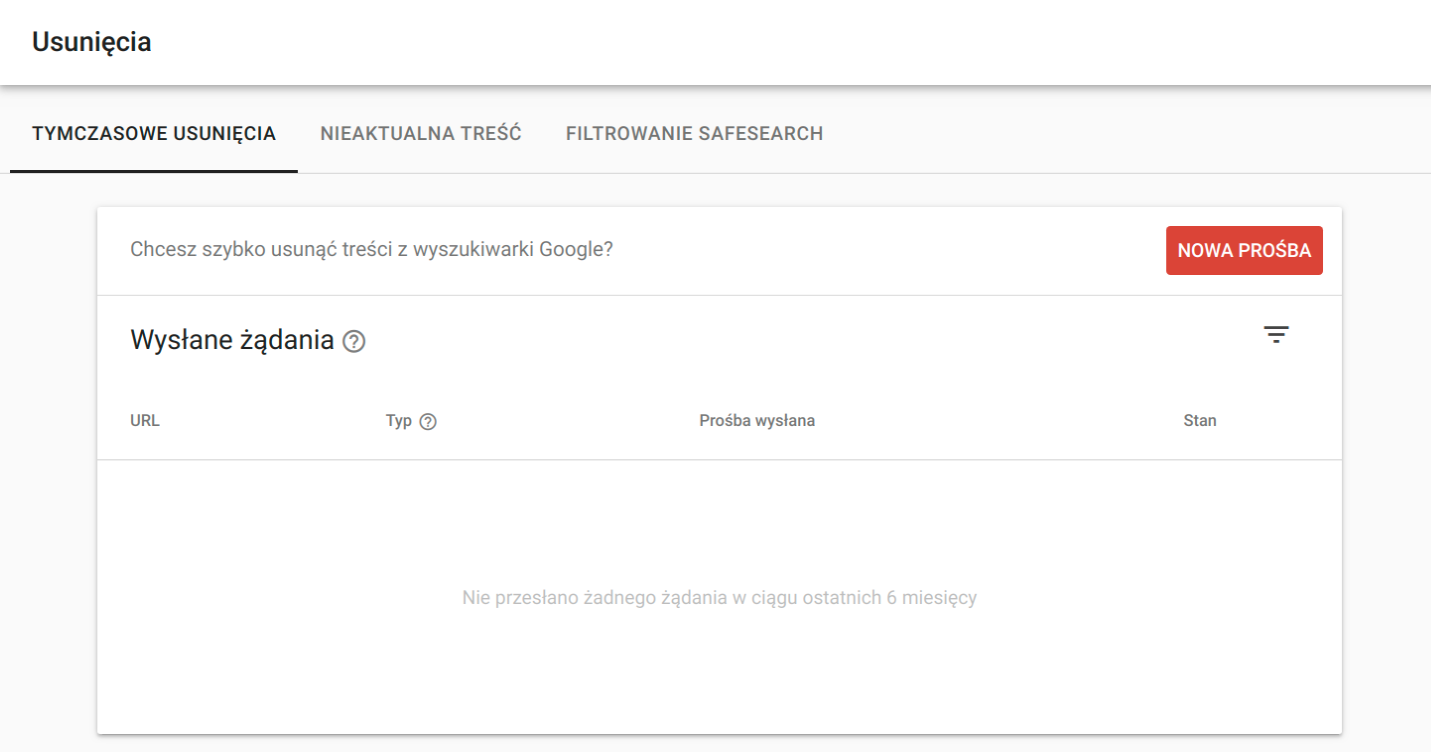
Skorzystanie z opcji „Usunięcia” w Google Search Console
Google Search Console pozwala wykluczyć z indeksu stronę, która została już zaindeksowana. Aby to zrobić, zaloguj się do Google Search Console i:
-
- przejdź do sekcji “Index” -> „Usunięcia”,
- wybierz zakładkę “Tymczasowe usunięcia”,
- kliknij w przycisk “Nowa prośba”,
- wybierz zakładkę „Tymczasowe usunięcie adresu URL”,
- wypełnij formularz, który pojawi się na ekranie.
Gotowe!
Uwaga! Korzystając z Google Search Console możesz jedynie tymczasowo wykluczyć strony z indeksu. Rezultat będzie utrzymywał się przez około 6 miesięcy. Jeżeli zależy Ci na stałym efekcie, użyj innych sposobów.
Dodanie adresu kanonicznego do podstrony
Meta tag zawierający adres kanoniczny podstrony (rel=”canonical”) służy do wskazania jej głównego adresu. Pozwala to uniknąć wewnętrznej duplikacji treści, która negatywnie wpływa na proces pozycjonowania.
Taka sytuacja może mieć miejsce, gdy kilka podstron ma bardzo podobną, albo nawet taką samą treść.
Meta tag kanoniczny informuje więc roboty indeksujące, że podstrona zawiera taką samą treść, jak podstrona, której adres jest podany za pomocą tego tagu i to wskazaną poprzez ten meta tag podstronę Google ma dodać do swojego indeksu. Podstrony zawierające meta tag z adresem kanonicznym innej podstrony zostają najczęściej usunięte* z indeksu wyszukiwarki. Meta tag zawierający kanoniczny adres podstrony wygląda tak:
<link rel=”canonical” href=”kanoniczny-adres-podstrony”/’>
* Warto mieć na uwadze, że w takich przypadkach Google może, ale nie musi usunąć takie podstrony z indeksu.
Dlaczego Google czasami samo usuwa podstrony z indeksu?
Czasami wyszukiwarka Google nie chce dodać do indeksu danej podstrony. Zdarza się też tak, że podstrona zostaje usunięta z indeksu wyszukiwarki. Dzieje się to pomimo tego, że indeksowanie danej podstrony nie jest zablokowane. Może dojść do tego w sytuacji, gdy:
-
- Podstrona zbyt długo się ładuje. Roboty indeksujące nie będą przecież czekać w nieskończoność…
- Podstrona nie działa.
- Podstrona ma dokładnie taką samą treść, co inna podstrona.
- Na podstronie znajduje się treść niskiej jakości.
- Na stronę została nałożona kara, na przykład za stosowanie technik Black Hat SEO.
- Roboty indeksujące mają techniczne problemy z indeksowaniem strony z powodu jej błędów.
Aby analizować stan indeksowania strony, dodaj ją do narzędzia Google Search Console. Sprawdzisz w nim m.in. to, jak roboty indeksujące Google “widzą” Twoją witrynę, a także uzyskasz informacje na temat błędów technicznych (również dotyczących indeksowania) oraz cenne podpowiedzi, jak je usunąć.
Źródła:


