
Na blogu Google dla webmasterów jakiś czas temu pojawił się wpis, który szczegółowo opisuje, jak powinna wyglądać optymalizacja nawigacji fasetowej pod kątem dostępności dla wyszukiwarek internetowych.
Nawigacja fasetowa (ang. faceted navigation) jest metodą nawigacji, z którą często spotykamy się w pracy nad rozbudowanymi serwisami internetowymi i szukamy optymalnych rozwiązań, które nie zawsze są oczywiste. Dlatego warto przytoczyć rozwiązania zalecane przez Google.
Co to jest w ogóle nawigacja fasetowa?
Nawigacja fasetowa, także wyszukiwanie fasetowe, przeglądanie fasetowe – system wyszukiwania oparty na klasyfikacji fasetowej, pozwalający użytkownikom na odnajdywanie zbiorów informacji posiadających cechy wspólne. W tym celu wykorzystywane są zestawy filtrów.
Nawigacja fasetowa, jak filtrowanie po kolorze czy przedziale cenowym, może być wygodna dla użytkowników strony internetowej, ale jest zwykle nieprzyjazna dla wyszukiwarek internetowych, ponieważ generuje wiele kombinacji adresów URL z powieloną treścią (ang. duplicate content).
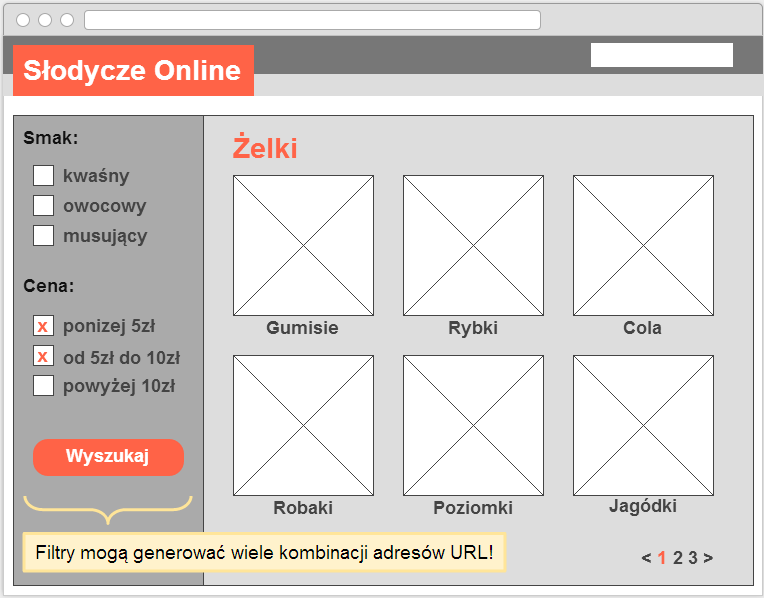
Z powodu URLi powielających treści wyszukiwarki mogą nie dotrzeć wystarczająco szybko do nowej lub zaktualizowanej zawartości oraz/lub mogą nie zaindeksować strony trafnie, ponieważ sygnały indeksowania są „rozcieńczone” pomiędzy zduplikowanymi wersjami.
Potencjalne problemy związane z nawigacją fasetową
W idealnej sytuacji unikalna zawartość (na przykład strona pojedynczego produktu czy kategorii produktów w sklepie internetowym) powinna być dostępna pod jednym unikalnym adresem URL. Taki adres URL powinien posiadać przejrzystą ścieżkę kliknięć (ang. click path) i być dostępny po kliknięciu ze strony głównej lub strony kategorii.
Rozwiązanie dobre dla użytkowników i wyszukiwarek
1. Ścieżka kliknięć prowadząca do stron z unikalną zawartością powinna być przejrzysta i musi pozwalać na dotarcie do wszystkich stron pojedynczych produktów.
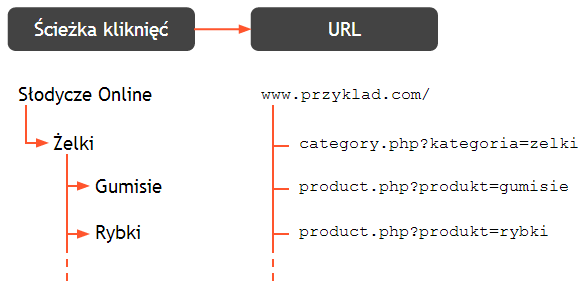
2. Każda strona kategorii powinna posiadać jeden reprezentatywny URL (np. http://www.przyklad.com/category.php?kategoria=zelki).
3. Każda strona produktu powinna posiadać jeden reprezentatywny URL (np. http://www.przyklad.com/product.php?produkt=gumisie).
Niepożądane powielanie spowodowane nawigacją fasetową
1. Generowanie wielu adresów URL dla strony tego samego produktu (wynik dodawania do adresu nadmiarowych parametrów URL).
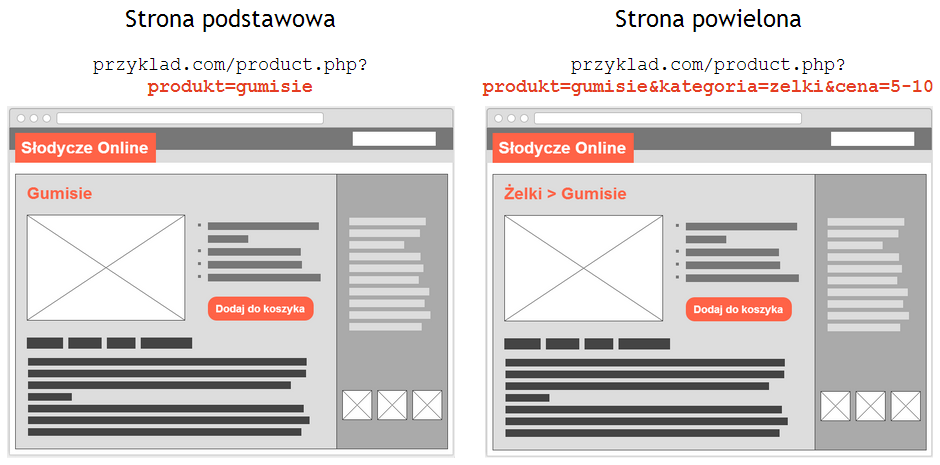
2. Generowanie wielu adresów URL dla strony tej samej kategorii, które stanowią niewielką lub żadną wartość dla użytkowników wyszukiwarek i samych wyszukiwarek internetowych (wynik filtrowania elementów).
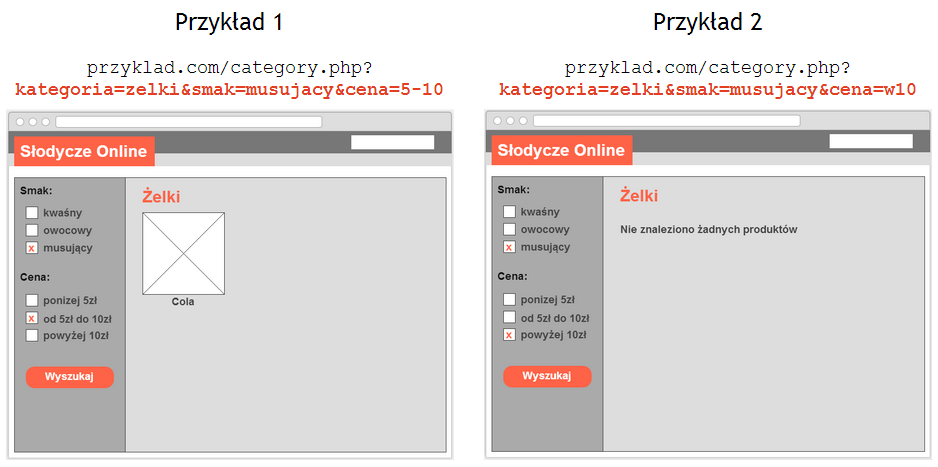
Przykład 1:
- Brak wartości dodanej dla użytkowników wyszukiwarek, ponieważ rzadko wpisują zapytania w rodzaju „żelki musujące w cenie od 5 do 10 złotych”.
- Brak wartości dodanej dla robotów wyszukiwarek, które odkryją ten sam produkt „Cola” na stronach kategorii nadrzędnych (“Żelki” czy “Musujące żelki”).
- Wartość ujemna dla właściciela witryny internetowej ze względu na „rozcieńczanie” sygnałów indeksowania między różne wersje strony tej samej kategorii.
- Wartość ujemna dla właściciela witryny internetowej ze względu na dodatkowy transfer danych i marnowanie zasobów wyszukiwarki (tzw. budżet indeksowania) na pobieranie zduplikowanej zawartości zamiast podstron nowych lub zaktualizowanych.
Przykład 2:
- Brak wartości dla wyszukiwarek internetowych – strona powinna zwracać kod odpowiedzi 404.
- Wartość ujemna dla użytkowników wyszukiwarek.
Najgorsze rozwiązania nawigacji fasetowej nieprzyjazne dla wyszukiwarek
1. Niestandardowe kodowanie parametrów URL
Złym rozwiązaniem jest niestandardowe kodowanie parametrów w adresach URL, takie jak wykorzystywanie przecinków czy nawiasów zamiast par klucz=wartość&.
Najgorsze praktyki:
- oznaczanie par klucz=wartość dwukropkiem (:) i rozdzielanie poszczególnych parametrów nawiasami kwadratowymi ([]), np.
przyklad.com/category?[kategoria:zelki][sort:cena-rosnaco][sid:789] - oznaczanie par klucz=wartość przecinkiem (,) i rozdzielanie poszczególnych parametrów podwójnym przecinkiem (,,), np.
przyklad.com/category?kategoria,zelki,,sort,cena-rosnaco,,sid,789.
Najlepsza praktyka:
- oznaczanie par klucz=wartość znakiem równości (=) i rozdzielanie poszczególnych parametrów znakiem ampersand (&), np.
przyklad.com/category?kategoria=zelki&sort=cena-rosnaco&sid=789.
Ludzie mogą rozkodować dziwne rozdzielanie parametrów URL, jak przecinki (,,), ale roboty wyszukiwarek mają problem z interpretacją parametrów URL zaimplementowanych w niestandardowy sposób.
Jak mówi jeden z pracowników Google odpowiedzialnych za indeksowanie, używanie niestandardowego kodowania parametrów URL jest proszeniem się o kłopoty. Dlatego należy używać znaku równości (=) do wskazywania par klucz=wartość i znaku ampersand (&) do łączenia wielu parametrów.
2. Katalogi zamiast parametrów niezmieniających zawartości strony
Kolejnym błędem jest używanie katalogów lub nazw plików zamiast parametrów URL do wskazywania wartości, które nie zmieniają zawartości strony.
Najgorsza praktyka:
- wskazywanie wartości niezmieniających zawartości strony (np. identyfikator sesji) w katalogu adresu URL, np.
przyklad.com/kat7/s789/product?gumisie, gdzie /kat7/ wskazuje kategorię, a /s789/ jest identyfikatorem sesji, który nie zmienia zawartości strony.
Dobra praktyka:
- wskazywanie w katalogach tylko wartości zmieniających w znaczący sposób zawartość strony, np.
przyklad.com/zelki/product.php?produkt=gumisie&sid=789, gdzie kategoria /zelki/ zmienia w znaczący sposób zawartość strony.
Najlepsza praktyka:
- wykorzystywanie parametrów URL, które dają wyszukiwarkom większą elastyczność w określaniu efektywnego indeksowania, np.
przyklad.com/product.php?produkt=gumisie&kategoria=zelki&sid=789.
Dla robotów wyszukiwarek trudnym zadaniem jest odróżnianie przydatnych wartości (np. „zelki”) od tych bezużytecznych (np. identyfikatory sesji), kiedy są one umieszczone bezpośrednio w ścieżce adresu URL (statyczne adresy URL).
Z drugiej strony parametry URL zapewniają wyszukiwarkom internetowym swobodę szybkiego testowania i ustalania czy dany parametr wymaga pobrania przez robota wszystkich jego wartości.
Popularne wartości, które nie zmieniają zawartości strony i powinny być wymieniane jako parametry URL, to:
- identyfikatory sesji
- identyfikatory śledzenia
- identyfikatory stron odsyłających
- sygnatury czasowe.
3. Wartości generowane przez użytkownika jako parametry URL
Błędnym rozwiązaniem jest również konwertowanie wartości generowanych przez użytkownika na prawdopodobnie nieograniczone parametry URL, które są pobieralne i indeksowalne, ale nieprzydatne w wynikach wyszukiwania.
Najgorsza praktyka:
- generowanie pobieralnych i indeksowalnych adresów URL w wyniku dodania w parametrach URL wartości generowanych przez użytkowników, np.
przyklad.com/znajdz-sklep?radius=15&latitude=40.7565068&longitude=-73.9668408lubprzyklad.com/artykuly?kategoria=lifestyle&days-ago=7.
Najlepsza praktyka:
- wykorzystanie predefiniowanych parametrów URL do stworzenia stron z wartościową zawartością, np.
przyklad.com/znajdz-sklep?miasto=warszawa&dzielnica=powislelubprzyklad.com/artykuly?kategoria=lifestyle&data=27-luty-2014.
Zamiast pozwalać na tworzenie dostępnych dla robotów adresów URL na podstawie wartości generowanych przez użytkownika, lepiej opublikować strony kategorii dla najbardziej popularnych wartości oraz zawrzeć dodatkowe informacje, dzięki czemu strona ma większą wartość niż zwykłe wyniki wyszukiwania.
Alternatywnie można rozważyć umieszczenie wartości generowanych przez użytkowników w oddzielnym katalogu, aby móc następnie zablokować jego indeksowanie w pliku robots.txt.
Przykładowo adresy:
przyklad.com/filtrowanie/znajdz-sklep?radius=15&latitude=40.7565068&longitude=-73.9668408,przyklad.com/filtrowanie/artykuly?kategoria=lifestyle&days-ago=7,
mogą być zablokowane przed indeksowaniem w pliku robots.txt wpisem:User-agent: *
Disallow: /filtrowanie/
4. Przypadkowe dodawanie parametrów URL
Brak kontroli nad dodawanymi parametrami URL powoduje spotęgowanie zjawiska powielania zawartości.
Najgorsze praktyki:
przyklad.com/zelki/lizaki/zelki/zelki/product?gumisieprzyklad.com/product?kat=zelki&kat=lizaki&kat=zelki&kat=zelki&produkt=gumisie
Lepsza praktyka:
przyklad.com/zelki/product?produkt=gumisie
Najlepsza praktyka:
przyklad.com/product?produkt=gumisie&kategoria=zelki
Nieistotne parametry URL tylko zwiększają powielanie zawartości, powodując mniej wydajne pobieranie i indeksowanie. Dlatego należy rozważyć pozbycie się niepotrzebnych parametrów URL i przeprowadzenie porządków w witrynie przed wygenerowaniem adresów URL.
Jeśli wymaganych jest wiele parametrów związanych z sesją użytkownika, prawdopodobnie lepiej będzie ukryć informacje w ciasteczku, zamiast dodawać kolejne wartości, np. kat=zelki&kat=lizaki&kat=zelki&…
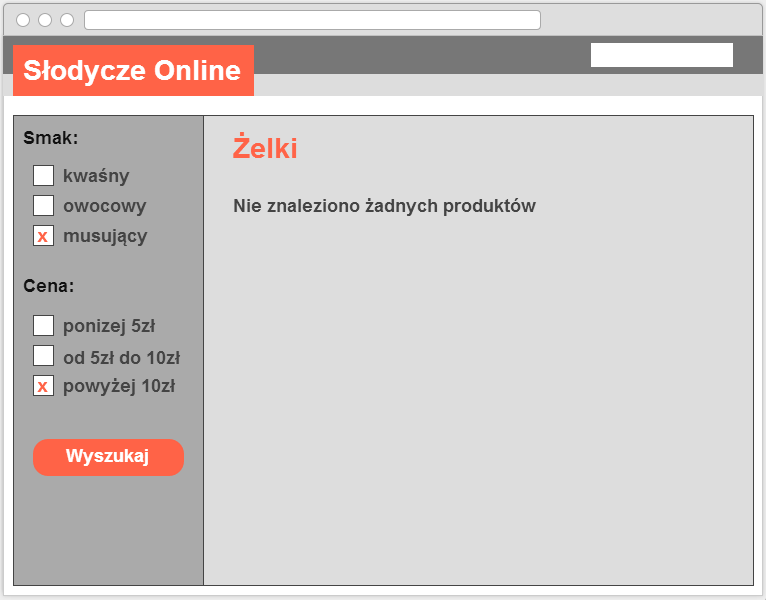
5. Udostępnianie dalszego filtrowania mimo zerowej liczby wyników
Najgorsza praktyka:
- Pozwalanie użytkownikom na dalsze wybieranie filtrów, mimo że dla obecnej konfiguracji zwracanych jest zero wyników.
Najlepsza praktyka:
- Linki/URLe powinny być generowane tylko wtedy, gdy prowadzą do zwrócenia jakichś elementów. W przypadku zerowych wyników opcje filtrowania powinny być wyłączone. Aby dodatkowo zwiększyć użyteczność, można rozważyć dodanie licznika elementów przy każdej opcji filtrowania.
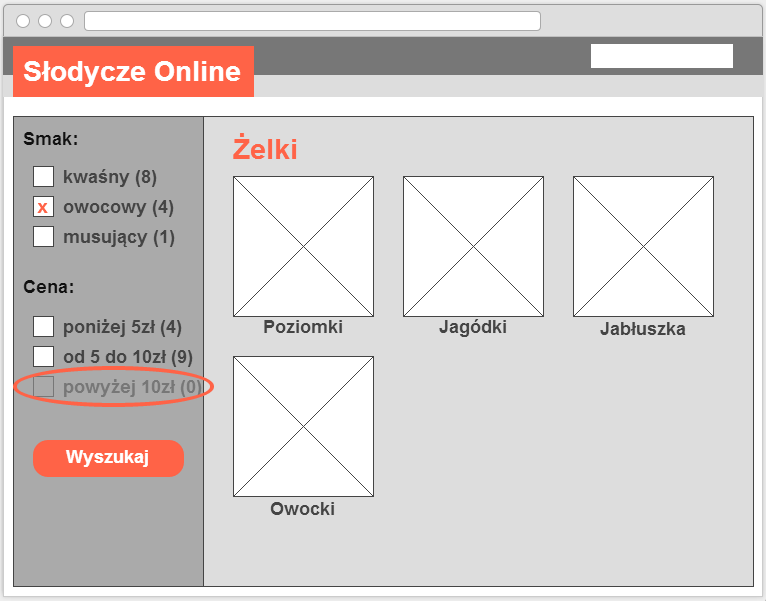
Należy zapobiegać generowaniu bezużytecznych adresów URL i minimalizować zakres adresów URL do pobierania przez tworzenie adresów URL jedynie w przypadku, gdy na stronie wynikowej zwracane są jakieś elementy. Pozwala to na utrzymanie zaangażowania użytkowników (rzadsza potrzeba cofania się w przypadku braku wyników) oraz pomaga zminimalizować liczbę adresów URL znanych robotom wyszukiwarek.
Ponadto jeśli strona jest pusta nie z powodu okresowej niedostępności towarów, ale jest mało prawdopodobne, że kiedykolwiek będzie prezentowała wartościową zawartość, warto rozważyć zwrócenie kodu 404. Poza odpowiedzią 404 można uwzględnić pomocny komunikat dla użytkowników z dodatkowymi opcjami nawigacji lub polem wyszukiwania, aby mogli odnaleźć powiązane produkty.
Najlepsze praktyki implementacji nawigacji fasetowej
Nowe serwisy internetowe, które rozważają zaimplementowanie nawigacji fasetowej, mają do wyboru kilka rozwiązań zawężających „obszar indeksowania” (wszystkie adresy URL w witrynie znane Googlebotowi) do stron z unikalną zawartością, a tym samym ograniczających pobieranie zduplikowanych stron i konsolidujących czynniki rankingowe.
1. Określenie wymaganych parametrów URL
Należy określić, które parametry URL są wymagane, aby wyszukiwarka internetowa mogła dotrzeć do każdej indywidualnej podstrony (strony poszczególnych produktów/artykułów). Wymagane parametry mogą obejmować item-id, category-id, page, itp.
2. Określenie wartościowych parametrów URL
Należy określić, które parametry będą wartościowe dla użytkowników wyszukiwarki i ich zapytań, a które będą tylko powodowały powielanie treści i niepotrzebne pobieranie oraz indeksowanie.
W przykładzie sklepu ze słodyczami można uznać, że parametr URL smak będzie wartościowy ze względu na takie zapytanie, jak „kwaśne żelki”, które może zwrócić w wynikach stronę przyklad.com/category.php?kategoria=zelki&smak=kwasne. Z kolei parametr price może być uznany za powodujący powielanie, jak strona kategoria=zelki&smak=kwasne&cena=w10.
Inne popularne przykłady:
- Parametry wartościowe dla użytkowników wyszukiwarki:
item-id,category-id,name,brand, … - Zbędne parametry:
session-id,price-range, …
3. Konfiguracja zbędnych parametrów URL
Należy wziąć pod uwagę implementację jednej z konfiguracji dla adresów URL zawierających zbędne parametry. Wcześniej trzeba się upewnić, że zbędne parametry nie są nigdy wymagane, aby użytkownik lub robot mógł dotrzeć do każdego pojedynczego produktu.
Opcja 1: rel=”nofollow” dla wewnętrznych linków
Rozwiązanie polega na oznaczeniu wszystkich linków prowadzących do niepotrzebnych adresów URL atrybutem rel=”nofollow”. Pozwala to zmniejszyć docieranie robotów wyszukiwarek do zbędnych adresów URL i tym samym ogranicza obszar indeksowania (URLe znane robotowi) generowany przez nawigację fasetową.
Atrybut rel=”nofollow” nie zapobiega pobieraniu adresów URL (jedynie blokada w pliku robots.txt zapobiega pobieraniu). Mimo pozwolenia na pobieranie niepotrzebnych adresów URL, można skonsolidować sygnały indeksowania z niepotrzebnych adresów URL w wartościowym adresie URL.
W tym celu należy na nadmiarowych podstronach dodać rel=”canonical” wskazujący na adres URL z rozszerzoną zawartością (np. przyklad.com/category.php?kategoria=zelki&smak=kwasny&cena=5-10 może za pomocą rel=”canonical” wskazywać na stronę ze wszystkimi kwaśnymi żelkami przyklad.com/category.php?kategoria=zelki&smak=kwasny&page=all).
Opcja 2: Blokada w pliku robots.txt
W adresach URL zawierających zbędne parametry należy uwzględnić specjalną kategorię, np. /filtrowanie/, która zostanie zablokowana w pliku robots.txt. Pozwoli to wszystkim wyszukiwarkom swobodnie pobierać wartościową zawartość, ale zapobiegnie pobieraniu niepożądanych adresów URL.
Przykładowo: wartościowymi parametrami są produkt, kategoria i smak, a zbędnymi parametrami są identyfikator sesji i cena.
W serwisie może występować adres URL:przyklad.com/category.php?kategoria=zelki,
który może linkować do kolejnego adresu URL z wartościowym parametrem:przyklad.com/category.php?kategoria=zelki&smak=kwasny.
Jednak w przypadku zbędnych parametrów, jak cena, URL zawiera predefiniowany katalog /filtrowanie/:przyklad.com/filtrowanie/category.php?kategoria=zelki&cena=5-10,
zablokowany w pliku robots.txt wpisem:User-agent: *
Disallow: /filtrowanie/
Opcja 3: Oddzielne hosty
Jeśli nie są wykorzystywane CDNy, można rozważyć umieszczenie każdego adresu URL zawierającego zbędne parametry na oddzielnym hoście.
Przykładowo głównym hostem może być www.przyklad.com, a dodatkowym www2.przyklad.com. Dla drugiego hosta (www2) należy w Narzędziach dla webmasterów ograniczyć szybkość indeksowania, utrzymując możliwie jak największą szybkość indeksowania hosta głównego (www). Pozwoli to na bardziej kompletne pobieranie adresów URL z głównego hosta i zredukuje pobieranie przez Googlebota zbędnych adresów URL.
- Należy upewnić się, że na głównym hoście jest dostępna przynajmniej jedna ścieżka kliknięć do wszystkich elementów.
- Aby skonsolidować sygnały indeksowania, należy dodać rel=”canonical” ze stron umieszczonych na drugim hoście (www2) do odpowiednich adresów URL na hoście głównym (np.
www2.przyklad.com/category.php?kategoria=zelki&smak=kwasny&cena=5-10powinna zawierać rel=”canonical” wskazujący nawww.przyklad.com/category.php?kategoria=zelki&smak=kwasny&page=all).
4. Dezaktywacja filtrów zwracających 0 wyników
Należy wyłączyć linki lub dezaktywować pola wyboru jeśli kategoria produktów lub filtr zawiera 0 produktów.
5. Określenie logiki dodawania parametrów URL
Parametry w adresach URL powinny być wyświetlane zgodnie z pewną logiką.
- Zbędne parametry należy usunąć zamiast w nieskończoność dodawać kolejne wartości (źle:
przyklad.com/product?kat=zelki&kat=lizaki&kat=zelki&produkt=gumisie) - Warto utrzymać spójną kolejność parametrów oraz wyświetlać jako pierwsze parametry wartościowe z punktu widzenia użytkowników wyszukiwarki, jako że adres URL może być wyświetlany w wynikach wyszukiwania.
6. Określenie kanonicznych adresów URL
Wykorzystanie tagu rel=”canonical” wskazującego na preferowaną wersję podstrony pozwala usprawnić proces indeksowania. Warto pamiętać, że rel=”canonical” może być używany między różnymi hostami lub domenami.
7. Rozwiązania dla zawartości stronicowanej
Należy usprawnić indeksowanie zawartości stronicowanej (np. page=1, page=2 i page=3 kategorii „żelki”), stosując jedno z rozwiązań:
- Dodając rel=”canonical” ze stron składowych paginacji do tzw. strony „view-all” (np. rel=”canonical” ze stron
page=1,page=2ipage=3kategorii „żelki” wskazujący na stronękategoria=zelki&page=all), upewniając się, że jest to rozwiązanie dobre z punktu widzenia użytkowników wyszukiwarki (np. strona z wszystkimi elementami ładuje się szybko). - Wykorzystując znaczniki rel=”next” i rel=”prev” w celu scalenia właściwości indeksowania stron składowych dla ich zestawu jako całości.
8. Rozwiązanie alternatywne do filtrowania JavaScript
Jeśli wykorzystywany jest JavaScript do dynamicznego sortowania/filtrowania/ukrywania zawartości bez zmiany adresu URL, należy upewnić się, że w witrynie dostępne są dla robotów wyszukiwarek wartościowe adresy URL, takie jak strony kategorii i produktów.
Przykładowo należy unikać stosowania jednego adresu URL dla całej witryny z wykorzystaniem JavaScript do dynamicznej zmiany zawartości. Ponadto trzeba sprawdzić czy dynamiczne filtrowanie nie wpływa negatywnie na wydajność, co mogłoby pogorszyć doświadczenia użytkowników.
9. Konfiguracja mapy witryny XML
W mapach witryny XML należy uwzględniać tylko kanoniczne adresy URL.
Najlepsze praktyki dla istniejących serwisów z nawigacją fasetową
Najlepsze praktyki implementacji fasetowej wskazane w poprzednim rozdziale odnoszą się także do istniejącego serwisu internetowego, o ile możliwe jest jego przeprojektowanie według tych zaleceń.
W przypadku już istniejącej nawigacji fasetowej jest bardzo prawdopodobne, że rozbudowany obszar indeksowania (ze zbędnymi adresami URL) został już odkryty przez wyszukiwarki internetowe. Dlatego należy skupić się na redukowaniu dalszego wzrostu stron niepotrzebnie pobieranych przez Googlebota i konsolidowaniu sygnałów indeksowania.
W tym celu należy:
- Stosować kiedy to możliwe parametry ze standardowym kodowaniem i w parach klucz=wartość&.
- Zweryfikować czy parametry niezmieniające zawartości strony, jak identyfikatory sesji, zostały zaimplementowane jako standardowe pary klucz=wartość, a nie katalogi.
- Zapobiegać generowaniu klikalnych linków i adresów URL, gdy dla wybranej kategorii lub filtrowania nie są zwracane żadne produkty.
- Uporządkować logicznie parametry w adresach URL. Usunąć zbędne parametry zamiast w nieskończoność dodawać kolejne wartości.
- Trzymać się stałej kolejności parametrów w adresach URL, jako pierwsze wymieniając parametry wartościowe z punktu widzenia użytkownika wyszukiwarki.
- W Narzędziach dla webmasterów skonfigurować parametry występujące w adresach URL. Pozwala to wskazać Googlebotowi jak dany parametr wpływa na zawartość strony oraz w jaki sposób powinien on pobierać adresy URL zawierające ten parametr.
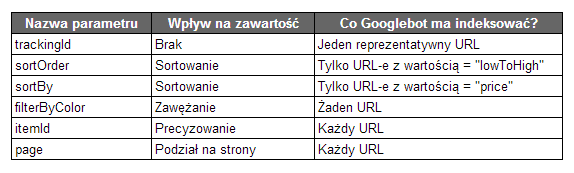
- Upewnić się, że w przypadku wykorzystywania kodu JavaScript do dynamicznego sortowania/filtrowania bez zmiany adresu URL, wartościowe podstrony są również dostępne pod indywidualnymi adresami URL. Dynamiczne filtrowanie nie powinno także wpływać negatywnie na wydajność stron.
- Poprawić indeksowanie stron poprzez wskazywanie znacznikiem rel=”canonical” preferowanej wersji podstrony.
- Usprawnić indeksowanie zawartości stronicowanej przez wskazanie strony zbiorczej jako wersji kanonicznej lub poprzez zastosowanie znaczników rel=”prev” i rel=”next”.
- W mapie witryny XML uwzględniać jedynie kanoniczne adresy URL, czyli te, które powinny być indeksowane przez wyszukiwarki internetowe.
A może znacie lepsze, sprawdzone rozwiązania funkcjonalności filtrów w witrynach internetowych?


